如何保障Go语言基础代码质量

为什么要谈这个 topic?
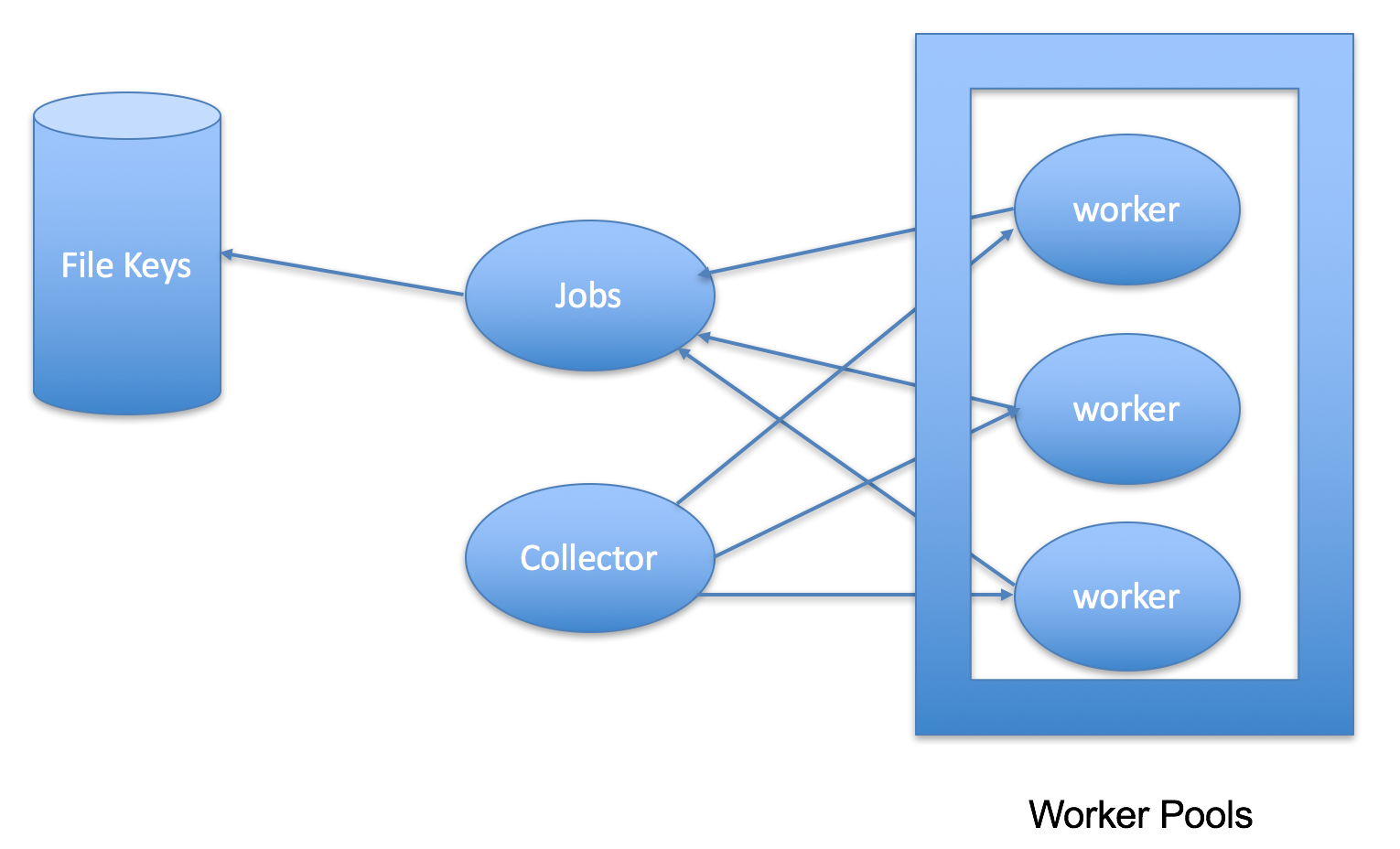
实践中,质量保障体系的建设,主要针对两个目标: 一是不断提高目标业务测试覆盖率,保障面向客户的产品质量;二就是尽可能的提高人效,增强迭代效率。而构建全链路质量卡点就是整个体系建设的核心手段。笔者用下图来描述这整个链路:

可以看到,虽然保障业务迭代的方向性正确排在最前面,但在具体操作上,这一步需要的是强化流程规范和构建企业文化,同时对各负责人技能培训,可以说多数是软技能。而保障基础代码质量环节发力于自动化建设链路之始,是可以通过技术手段来消灭潜在的质量问题,所以构建好的话能极大的降低心智负担,非常值得关注。
我们都知道,代码的好坏会直接影响到业务质量,团队协作,以及后期技术债等。有一个经典的图来描述代码质量的好坏,当能深切表达程序员的内心:

而同时我们相信,绝大部分程序员都有追求卓越的初心,且会尽可能的在自己能力范围内编写高质量的代码。
但是,��保障基础代码质量光靠程序员的个人素质一定是不全面,是人就会犯错,可能会疏忽。我们最需要的是一种自动化的机制来持续确保不出问题。这也是自动化的魅力,一次构建,持续收获价值。
此类工具在业界一般叫 linter,不同的语言有不同的实现。本文主要探究 Go 语言相关的。
在介绍相关工具之前,我们先看看几个经典的代码坏味道:
 这段代码常规运行不会有问题,但是在一些场景下循环执行,那可能就会有问题了, 我们来看看:
这段代码常规运行不会有问题,但是在一些场景下循环执行,那可能就会有问题了, 我们来看看:
 (注:ex2 是上述代码编译出的可执行文件名字)
(注:ex2 是上述代码编译出的可执行文件名字)

很明显,有句柄泄露。原因也很简单,http response 的 body 没有关闭。但这个关闭语句,一不注意也容易写错:

这时候如果百度挂了,上述程序程序就会因为空指针引用,造成非预期的 panic,非常的不优雅。所以正确的做法应该是在 err 判断之后再行关闭 body(关于 Client.Do 具体的各种限制,大家可以参考这里: https://golang.org/pkg/net/http/#Client.Do)
如此种种,此类小问题在实际编码活动中非常常见,且不容易一眼看出问题。甚至常规的测试可能也难检测出来,可谓非常棘手。好在 Go 语言的开发者们为我们想到了这一点,内置工具链中的 vet 命令,就能方便的检测到很多类似的问题。

还比如下面的代码场景,我在实际的测试用例和业务代码都看到过:

go vet 可以很容易检测出这个问题(其他 vet 功能,可以参考这里: https://golang.org/cmd/vet/)。

go 的工具链中,还有一个不得不提,那就是大名鼎鼎的 go fmt,其了却了其他语言经常陷入的代码风格之争,是 Go 语言生态构建非常巧妙的地方。另外 golint 也是 google 主推的 go 语言代码代码风格工具,虽非强制,但强烈建议新项目适用。
Go linters 业界现状
上面主要说到 Go 工具链的内置工具,还有一些非官方的工具也比较有名,比如 staticcheck, errcheck在 github 上 Star 都较多。此类工具有个专门的的 github 库,收集的比较全,参见 awesone-static-analysis
同时还有些项目旨在聚合此类工具,提供更方便的使用方式,以及一些酷炫的产品化。比如golangci-lint, 其衍生的商业化项目,可以自动针对 github PR 做代码审核,对有问题的地方自动 comments,比较有意思。
如何才能优雅的落地 linter 检查?
linter 工具必须为产品质量服务,不然就是做无用功。实践中,我们应该思考的是如何才能优雅的落地 linter 检查,如何才能建立有效的质量卡点。
推荐针对 PR,做代码检查,保障入库代码质量。基于 PR 做事情是我比较看好的,因为这是调动所有研发力量,天然契合的地方。且进一步讲,这也是测试基础设施更能体现价值的地方。
目前 Github 上有很多这方面的集成系统做的都比较好,能够快速的帮我们落地 PR 测的检查,比如 Travis, Circle CI 等。另外就是著名的 Kubernetes 社区,也自行构建了强大的 Prow 系统,其不光是基于 CICD 系统,还构建了 chat ops 模式,为参与 Kubernetes 的社区的贡献者提供了方便。
细看 Kubernetes 库,会发现,其会针对每个 PR 都做如下静态检查:
- gofmt: https://github.com/kubernetes/kubernetes/blob/master/hack/verify-gofmt.sh
- govet: https://github.com/kubernetes/kubernetes/blob/master/hack/make-rules/vet.sh
- golint: https://github.com/kubernetes/kubernetes/blob/master/hack/verify-golint.sh 因为 golint 只是纠正代码风格,并不是强制,所以 k8s 官方就弄了比较软的方案,对于当前已经存在的代码如果有问题,先排除掉(如下)。对于新生代码,如果检查失败,ci 就挂掉。 https://github.com/kubernetes/kubernetes/blob/master/hack/.golint_failures
Kubernetes 只利用了官方的几款工具, 在检测准确性上比较有保障。有了这些检查点,也能倒逼研发人员关注提交代码的质量,会迫使其在本地或者 IDE 上就配置好检查,确保每次提交的 PR 都能通过检查,不浪费 CI 资源。这也是合格工程师的基本要求。
总结
高质量的代码是业务质量保障的基础。而编写高质量的代码是技术问题,同时也应该是企业文化问题。因为当大家都开始注重技术,注重代码质量时,自然会朝着精益求精的路上行进,视糟糕的代码为仇寇。
我的一位老板跟我说过,要做就做 Number One。而在没达到第一的时候,那就要向业界标杆看齐,比如 Netflix,Google,Facebook 等。当大家都非常注重自己代码质量时,工程师才有时间去关注解决更加系统性的问题,而不用一直在 Low Level 徘徊。笔者深以为然。