Go1.20 新版覆盖率方案解读

玩过 Go 覆盖率的同学当有所了解,Go 的覆盖率方案最初的设计目标仅是针对单测场景,导致其局限性很大。而为了适配更多的场景,行业内各种博客、插件、黑科技介绍也层出不穷。当然,过去我们也开源过 Go 系统测试覆盖率收集利器 - goc,算其中比较完善,比较系统的了。且从用户使用角度来看,goc 也确实解决了行业内很多同学的痛点。
而现在,Go 官方终于开始正式这个问题了。作者Than McIntosh 于今年 3 月份提出了新的覆盖率提案,且看当前实现进度,最快 Go1.20 我们就能体验到这个能力,非常赞。
- https://github.com/golang/go/issues/51430
- https://go.googlesource.com/proposal/+/master/design/51430-revamp-code-coverage.md
基于作者的 Proposal,我们先来看看这个提案细节。
新姿势: go build -cover
需要明确的是,本次提案不会改变原来的使用姿势go test -cover,而是新增go build -cover使用入口。从这一变化我们不难看出,新提�案主要瞄准的是 "针对程序级的覆盖率收集" ,而旧版的实际是 "仅针对包级别的覆盖率收集" ,二者设计目标有明显的差别。
在新姿势下,使用流程大体是:
$ go build -o myapp.exe -cover ...
$ mkdir /tmp/mycovdata
$ export GOCOVERDIR=/tmp/mycovdata
$ <run test suite, resulting in multiple invocations of myapp.exe>
$ go tool covdata [command]
整体逻辑也比较清晰:
- 先编译出一个经过插桩的被测程序
- 配置好覆盖率输出的路径,然后执行被测程序。到这一步程序本身就会自动的输出覆盖率结果到上述路径了
- 通过
go tool covdata来处理覆盖率结果
这里的子命令 covdata 是新引入的工具。而之所需要新工具,主要还是在新提案下,输出的覆盖率文件格式与原来的已有较大的差别。
新版覆盖率格式
先来看旧版的覆盖率结果:
mode: set
cov-example/p/p.go:5.26,8.12 2 1
cov-example/p/p.go:11.2,11.27 1 1
cov-example/p/p.go:8.12,10.3 1 1
cov-example/p/p.go:14.27,20.2 5 1
大家当比较熟悉,其是文本格式,简单易懂。
每一行的基本语义为 "文件:起始行.起始列,结束行.结束列 该基本块中的语句数量 该基本块被执行到的次数"
但缺点也明显,就是 "浪费空间". 比如文件路径 cov-example/p/p.go, 相比后面的 counter 数据,重复了多次,且在通常的 profile 文件,这块占比很大。
新提案在这个方向上做了不少文章,实现细节上稍显复杂,但方向较为清晰。
通过分析旧版的每一行能看出,本质上每一行会记录两类信息,一是定位每个基本块的具体物理位置,二是记录这个基本块的语句数量和被执行的次数。虽然执行的次数会变化,但是其他的信息是不变的,所以全局上其实只要记录一份这样的信息就好,而这就能大大的优化空间,
所以,新版覆盖率它实际会实际输出两份文件,一份就是 meta-data 信息,用于定位这个被测程序所有包、方法等元信息,另一份才是 counters,类似下面:
➜ tmp git:(master) ✗ ls -l
total 1280
-rw-r--r-- 1 jicarl staff 14144 Nov 28 17:02 covcounters.4d1584597702552623f460d5e2fdff27.8120.1669626144328186000
-rw-r--r-- 1 jicarl staff 635326 Nov 28 17:02 covmeta.4d1584597702552623f460d5e2fdff27
这两份文件都是二进制格式,并不能直观的读取。但是借助covdata工具,可以轻松转化为旧版格式,比较优雅。类似:
go tool covdata textfmt -i=tmp -o=covdata.txt
ps:
tmp��是覆盖率文件所在目录。
真 • 全量覆盖率
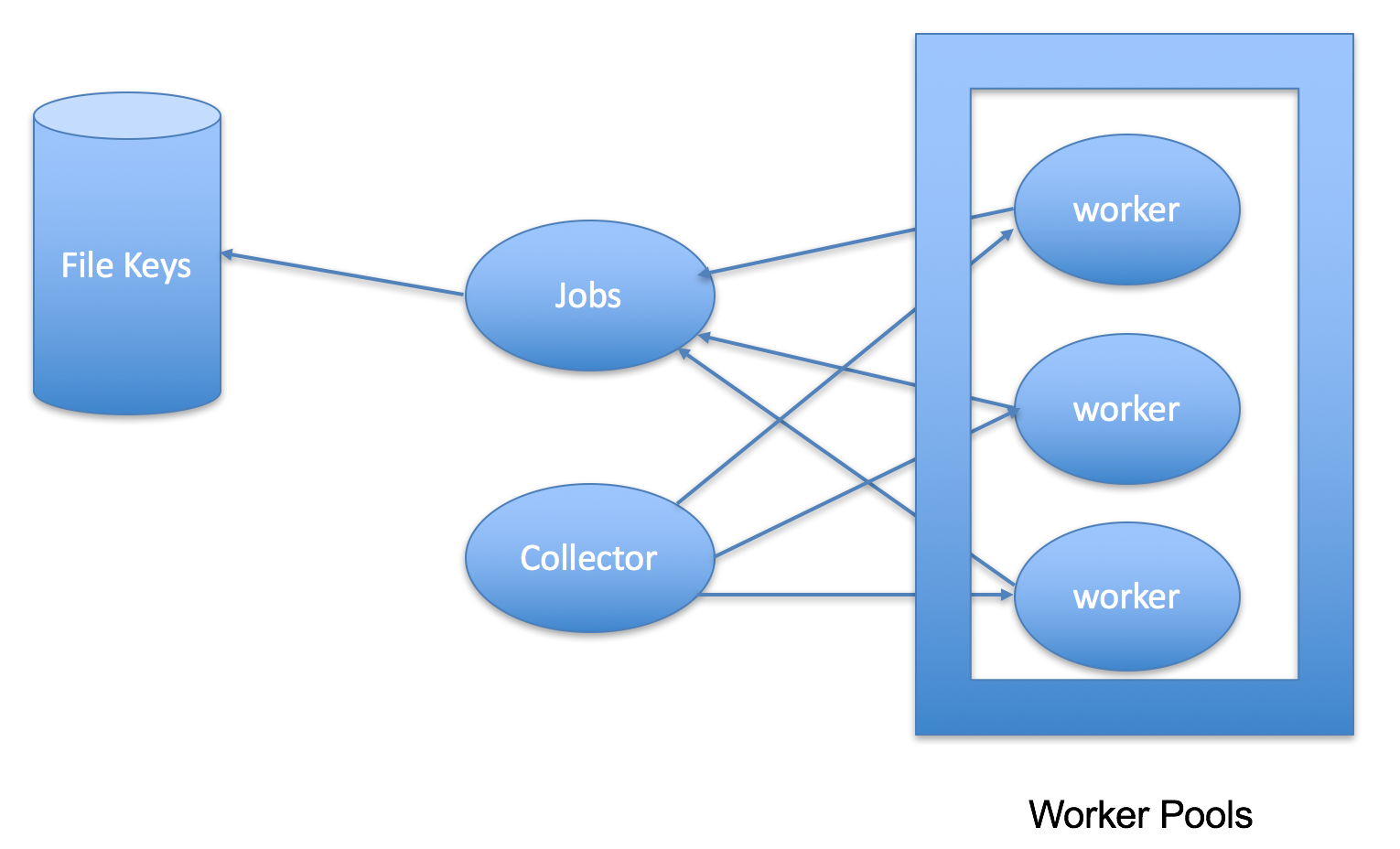
一个标准的 go 程序,基本上由三种类型的代码包组成:
- 自身代码
- 第三方包,通过 mod 或者 vendor 机制引用
- go 标准库
在过去,几乎所有的工具都只关注业务自身代码的插桩,鲜少关注第三方包,更别说 go 官方标准库了。这在大部分场景下是没问题的,但有时有些场景也有例外,比如 SDK 相关的项目。因为这时候 SDK 会作为 Dependency 引入,要想对其插桩就需要额外的开发量。还比如一些 CLI 程序,执行完命令之后,立马就结束了,也是非常不利于覆盖率收集的。
这些问题都是很现实的,且我们在 goc 项目中也收到过真实的用户反馈:
不过,现在好了,新版覆盖率方案也有实际考虑到这些需求,它实际会做到 支持全量插桩+程序退出时主动输出覆盖率结果 的原生方式,非常值得期待。
更多覆盖率使用场景支持: 合并(merge)、删减(subtract)、交集(intersect)
在实际处理覆盖率结果时,有很多实用的场景,在新提案中也有提及,比如支持:
- 合并多次覆盖率结果
go tool covdata merge -i=<directories> -o=<dir> - 删减已经覆盖的部分
go tool covdata subtract -i=dir1,dir2 -o=<dir> - 得到两份结果的交集
go tool covdata intersect -i=dir1,dir2 -o=<dir>
在过去,这些场景都需要依赖第三方工具才行,而在新方案中已经无限接近开箱即用了。
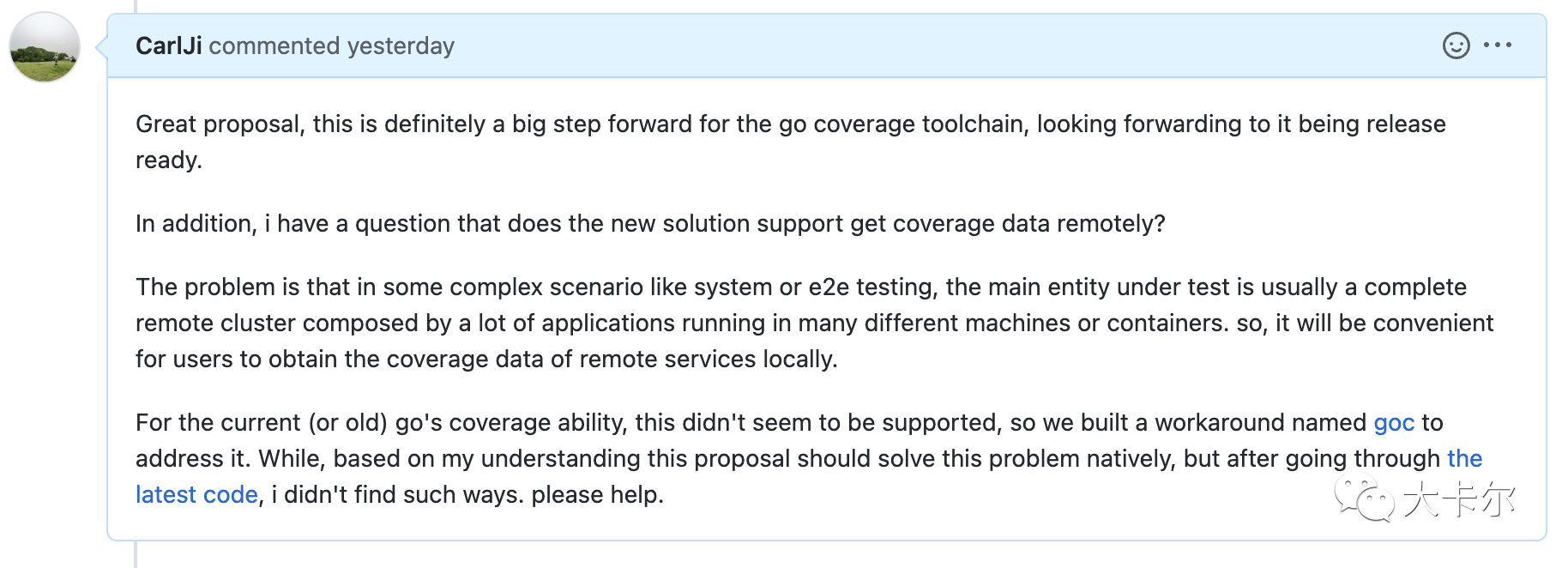
不过更复杂的场景,类似远程获得覆盖率结果等(类似 goc 支持的场景),看起来新方案并没有原生支持。这个问题,笔者也在 issue 讨论中提出,看看作者是否后续有解答。
展望与不足
值得注意的是新提案的实现是通过 源码插桩+编译器支持 的方式来混合实现的,与原来go test -cover 纯源码改写的方式有了较大的变化。
另外作者提到的 test "origin" queries 功能还是非常让我兴奋的,因为有了它,若想建立 测试用例到源码的映射 会变得简单很多,甚至更进一步的 精准测试,也变的更有想象空间。不过这个功能不会在 Go1.20 里出现,只能期待以后了。
作者还提到了一些其他的限制和将来可能的改进,比如 Intra-line coverage, Function-level coverage, Taking into account panic paths 等,感兴趣的同学可以自行去 Proposal 文档查看。







 这段代码常规运行不会有问题,但是在一些场景下循环执行,那可能就会有问题了, 我们来看看:
这段代码常规运行不会有问题,但是在一些场景下循环执行,那可能就会有问题了, 我们来看看:
 (注:ex2 是上述代码编译出的可执行文件名字)
(注:ex2 是上述代码编译出的可执行文件名字)