TopoLVM - 基于LVM的Kubernetes本地持久化方案,容量感知,动态创建PV,轻松使用本地磁盘

正文
研发测试场景下,一般追求的是一键快速起环境,横向动态复制,一人一套,随起随用,用完即走。作为使用方,其不用关心实际的物理资源是怎样的,环境起在哪里,只要声明自己的使用需求即可。但作为方案构建者以及 infrastructure 支撑,我们却深知,要想提供更好的解决方案,个中问题还有很多,且颇为不易。
比如在过去,笔者就曾一度困扰于如何优雅的放开本地物理盘给业务使用这个问题,尤其是本地 HDD 数据盘。
这里有个背景,我们的 Kubernetes 研发测试集群是用线上退下来的过保机器搭建,然后七牛又搞云存储,所以我们的机器中很多那种多盘位的存储密集型机器(比如挂 12 块 4T 的盘)。所以如何更好的利用这些磁盘,就是个问题。 方案之一是把这些盘组成网络存储,然后通过七牛自身的云服务或者 ceph 等系统提供出去,这当然是可行的。不过有些业务其实就想单纯使用物理盘,那该怎么办呢?
纵观 Kubernetes 目前原生提供的几种方案,笔者发现都不完美:
- Emptydir 非持久化方案,Pod 删除,EmptyDir 也会被清空。另外 Emptydir 使用的是 rootfs 的存储空间,而这个空间有可能是放在在系统盘上的,所以对它的使用当慎之又慎。
- HostPath 持久化方案,但安全风险很高,官方不推荐。另外,从使用角度也不方便。比如作为用户,你首先要清楚知道目标系统的情况,知道具体的盘符和目录位置然后才能在 HostPath 里正确引用。但现实是从集群安全角度,用户不一定有直接登录机器的权限。另外即使你的 Pod 占了某个宿主机的目录,也不能排除别人二次占用,或者误操作。所以 HostPath 的使用场景实际很受限。
- Local Persistent Volume 持久化方案,以 PVC/PV 的形式来使用本地存储。想法很好,但是不能动态创建 PV,对于 PV 提供者来说,心智负担较高。当然社区现在也有提供 Local Static Provisioner,某种程度上简化了这块的心智负担,但是仍然需要预先规划目录或者分区,略显不足。
笔者以为,理想中的本地磁盘使用方案,应当是按需申请,空间隔离,且自动化生命周期管理。这样才能既方便终端用户使用,也能减少运维支撑,提高效率。这里的关键技术点有三个:
- 按需申请 意味着最好以 PVC+StorageClass 的模式来提供服务,做到 PV 动态创建。而要实现这点,容量感知 是关键,因为若调度到空间不足的节点上很明显是不合理的。最好能结合 PVC 申请的容量+Node 上的剩余容量,综合选择最优的节点来做绑定。
- 空间隔离 要确保用户申请的空间大小一定是足额的,不被侵占的。从这里看,单纯的把文件系统的目录用作 PV 但容量上彼此不隔离显然不合适。
- 自动化生命周期管理 动态 Provisioning 是强需。
综合以上三点,我们会发现基于 LVM 或分区技术+CSI 的实现,当是比较符合上述用户体验的,而TopoLVM就是这样一个项目。
TopoLVM 是基于 LVM 的 Kubernetes 本地化磁盘方案,以 CSI 形式提供给用户使用。目前主要支持以下功能:
- 动态 Provisioning
- 支持原生数据块卷(Raw Block Volume)
- Volume 伸缩
整体架构如下:
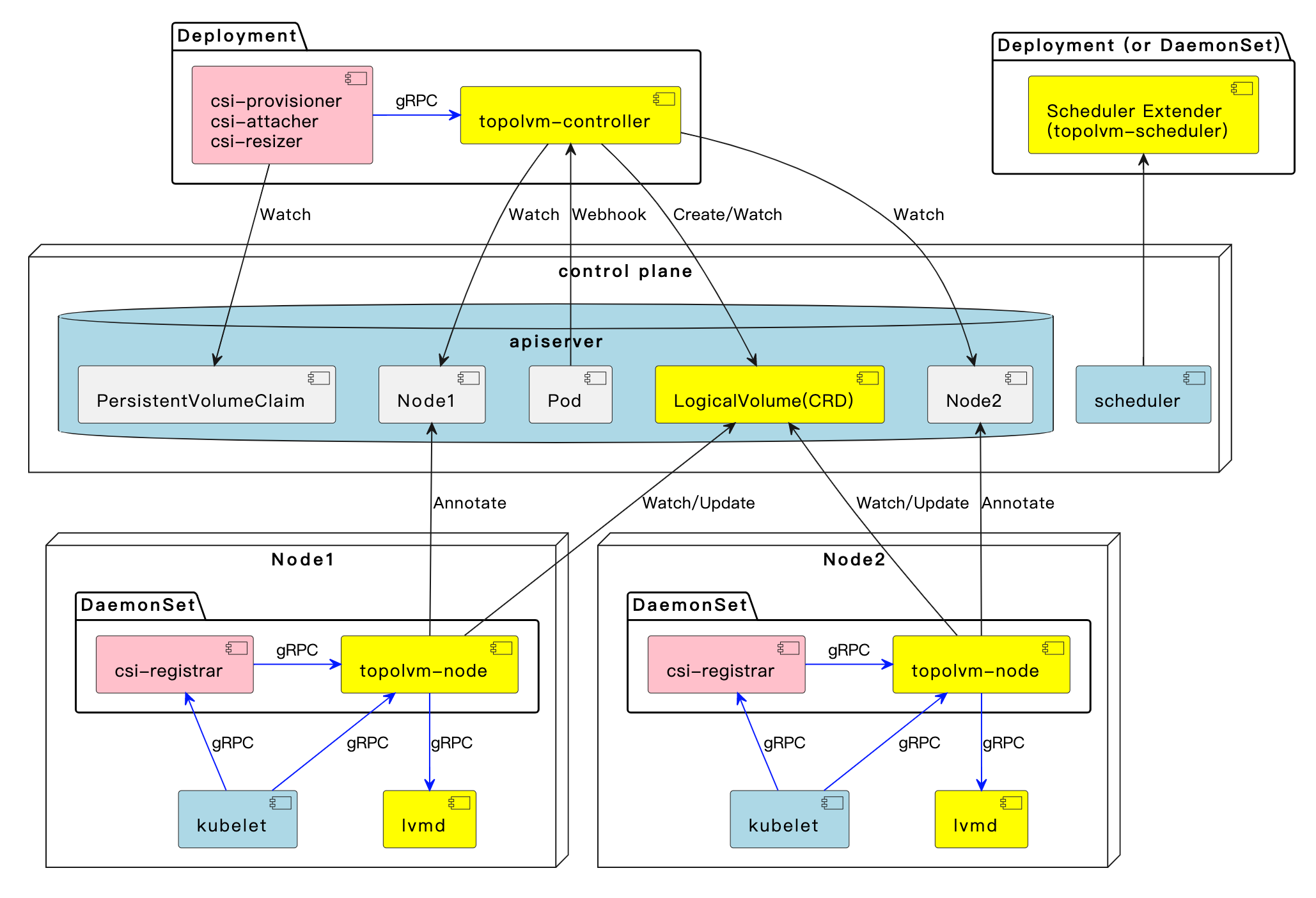
值得注意的是,在早期版本,为了能够动态感知节点上的剩余存储容量,TopoLVM 设计了个自定义扩展调度器(上图 topolvm-scheduler 部分),方便在 Scheduling 阶段为 Pod 绑定合适的 Node。而在 Kubernetes 1.21 之后,Kubernete 已经原生支持了 Storage Capacity Tracking的能力,这块的实现整体就变的优雅很多,topolvm-Scheduler 也就不再需要了。
当然,要想认知到 TopoLVM 的核心原理,除了了解 CSI 编写规范外,最重要的就是需要了解 LVM 相关技术。而正是因为通过 LVM 能够动态创建 LV,动态扩缩容,TopoLVM 才能支持动态 Provisioning 相关的能力。
不过,虽然作为开源项目 TopoLVM 已基本够用,但丰富度略显不足。而博云近期也开源了他们的云原生本地磁盘管理方案 Carina,看起来更完善一些。
Carina 除了提供基于 LVM 的方案外,还支持裸盘分区方式,以及 IOPS 限制等,功能更加丰富。代码组织规范也更贴合云原生社区的方式,整体非常值得一探。
参考链接
- Volume: https://kubernetes.io/docs/concepts/storage/volumes/
- PV: https://kubernetes.io/docs/concepts/storage/persistent-volumes/
- Storage Capacity: https://kubernetes.io/docs/concepts/storage/storage-capacity/
- LVM: https://en.wikipedia.org/wiki/Logical_Volume_Manager_(Linux)

 (PS: 2019 年 4 月发布)
(PS: 2019 年 4 月发布)